
El problema
Tengo cientos de documentos técnicos — PDFs de investigación, guías, notas en Markdown. Cada vez que necesito encontrar algo específico, termino haciendo Ctrl+F en 20 archivos diferentes. Los servicios cloud de RAG existen, pero enviar documentos sensibles a servidores de terceros no es opción.
Quería algo que corriera 100% local, sin API keys, sin que mis datos salgan de mi red.
Qué es Mindvault
Un agente RAG full-stack que permite subir documentos (PDF, TXT, Markdown) y chatear con ellos usando cualquier LLM. Todo corre en tu máquina.
El stack:
- Backend — FastAPI + Pydantic AI
- Vector DB — Qdrant (HNSW + full-text search)
- LLM — Ollama, OpenAI, Inferencer Pro, vLLM, Groq (multi-provider)
- Embeddings — bge-m3 (1024d) via Ollama o cualquier servidor OpenAI-compatible
- iOS — SwiftUI con streaming SSE
- Android — Jetpack Compose + OkHttp
Arquitectura
El sistema tiene 3 capas principales:
Capa de clientes — Apps nativas iOS y Android que se comunican via HTTP + SSE (Server-Sent Events) con el backend. Cada token del LLM se transmite en tiempo real.
Capa de backend — FastAPI con 4 grupos de routers: health, documents, chat, sessions. El agente de Pydantic AI orquesta 4 tools de búsqueda y el retriever híbrido se conecta a Qdrant.
Capa de infraestructura — Qdrant como vector DB (HNSW + full-text), Ollama (o cualquier OpenAI-compatible) para LLM y embeddings, SQLite para sesiones persistentes.
Pipeline de ingestion
Cuando subes un documento, pasa por un pipeline de 5 etapas:
Input File ──→ 1. Dedup ──→ 2. Parse ──→ 3. Chunk ──→ 4. Embed ──→ 5. Store
PDF/TXT/MD Replace if Extract Structural bge-m3 Qdrant
same name text+meta split batch x32 upsert x1001. Deduplicación
Si ya existe un documento con el mismo nombre, se elimina primero y luego se inserta el nuevo. Esto evita duplicados al re-subir versiones actualizadas.
# Primero borrar, luego insertar — evita race conditions
for old_id in old_doc_ids:
await self.store.delete_document(old_id)
await self.store.upsert_chunks(
doc_id=doc_id,
chunks=chunks,
vectors=vectors,
)2. Parsers
Tres parsers especializados extraen texto y metadata según el formato:
| Formato | Librería | Metadata extraída |
|---|---|---|
| PyMuPDF + Tesseract OCR | autor, subject, keywords, creation_date, page_map | |
| TXT | stdlib | encoding (fallback chain: utf-8 → latin-1 → cp1252) |
| Markdown | custom | frontmatter YAML, primer H1 como título |
El parser de PDF ahora incluye OCR automático para páginas escaneadas. Si una página no tiene texto embebido, se renderiza a imagen y se procesa con Tesseract:
for i, page in enumerate(doc):
text = page.get_text("text")
if text.strip():
pages_text.append(text.strip())
page_numbers.append(i + 1)
elif ocr_enabled:
# Página escaneada — renderizar a imagen y OCR
pix = page.get_pixmap(matrix=fitz.Matrix(2, 2)) # 2x resolución
img = Image.open(io.BytesIO(pix.tobytes("png")))
ocr_text = pytesseract.image_to_string(img, lang=language)
pages_text.append(ocr_text.strip())
page_numbers.append(i + 1)Además, el parser construye un page_map que mapea offsets de caracteres a números de página. Esto permite que cada chunk sepa de qué páginas viene:
# page_map: [(char_offset, page_number), ...]
page_map = []
offset = 0
for text, page_num in zip(pages_text, page_numbers):
page_map.append((offset, page_num))
offset += len(text) + 23. Chunking estructural
No uso sliding window genérico. El chunker analiza la estructura del documento:
chunk_size = 1200 # target en chars
chunk_overlap = 200 # overlap sentence-aligned
max_chunk_size = 2000 # nunca exceder
min_chunk_size = 80 # descartar fragmentos muy cortosReglas de splitting:
| Regla | Comportamiento |
|---|---|
| Code blocks | Atómicos — nunca se cortan mid-fence |
| Headers H1/H2 | Fuerzan boundary (strong split) |
| Headers H3-H6 | Se mergen al chunk actual si caben |
| Párrafos | Punto de split cuando se excede el target |
| Overlap | Últimas N frases del chunk[i] se prependen a chunk[i+1] |
| Section tracking | Cada chunk guarda el header padre como metadata |
El overlap es por frases completas, no por caracteres. Esto preserva coherencia semántica en los bordes:
def _get_tail_sentences(self, text: str, max_chars: int) -> str:
sentences = self._split_sentences(text)
tail = []
total = 0
for s in reversed(sentences):
if total + len(s) > max_chars:
break
tail.insert(0, s)
total += len(s) + 1
return " ".join(tail).strip()4. Embeddings en batch
Los embeddings se generan con bge-m3 (1024 dimensiones) en batches de 32 textos por llamada. Esto da un speedup de 3-5x respecto a embeddings individuales.
Soporta dos proveedores:
- Ollama — endpoint nativo
/api/embed - OpenAI-compatible — endpoint estándar
/v1/embeddings(Inferencer Pro, vLLM, LM Studio)
# Dispatch automático según EMBEDDING_PROVIDER
async def _embed_single(self, text: str) -> list[float]:
if self._provider == "openai-compatible":
return await self._openai_single(text)
return await self._ollama_single(text)Si un batch falla, hay fallback individual para no perder todo el documento:
try:
vecs = await self._embed_many(batch_texts)
except Exception:
# Fallback: embed uno por uno
for orig_idx, txt in batch:
results[orig_idx] = await self._embed_single(txt)Búsqueda híbrida
El retriever combina dos señales de relevancia:
User Query
├──→ Embed (bge-m3 → vector 1024d) ──→ Vector Search (HNSW, ef=128)
└──→ Stopword Filter ──→ Keyword Extraction ──→ Full-Text Search (Qdrant)
│
Score Fusion ←────────────────────────┘
│
Diversification (max 3 per doc)
│
Reranker (cross-embedding)
│
Context Expansion (±1 chunk)
│
Ranked Results → AgentScore fusion
Para cada chunk encontrado por vector search:
text_bonus = 1.0 if hit.id in text_ids else 0.0
combined = hit.score * (1 - text_weight) + text_bonus * text_weight
# Con text_weight=0.3:
# combined = vector_score * 0.7 + text_bonus * 0.3Los chunks que aparecen en ambas búsquedas obtienen un boost del componente keyword. Esto es clave para queries con nombres propios, números o acrónimos donde la similitud semántica sola no es suficiente.
Diversificación
Sin diversificación, si subes un documento de 200 páginas sobre un tema, todos los top-K resultados vienen de ese documento. El diversificador limita a 3 resultados por documento y llena los slots restantes con chunks de otros documentos:
_MAX_PER_DOCUMENT = 3
for r in results:
count = doc_counts.get(r.document_id, 0)
if count < _MAX_PER_DOCUMENT:
diverse.append(r)
doc_counts[r.document_id] = count + 1
else:
overflow.append(r)
# Backfill si no hay suficientes docs diversos
if len(diverse) < top_k:
diverse.extend(overflow[:top_k - len(diverse)])Reranker
Después de la fusión, un reranker re-evalúa los resultados usando cross-embedding similarity. Para cada resultado, embede "query: {query} passage: {chunk}" y calcula la similitud coseno contra el embedding del query solo:
pairs = [f"query: {query} passage: {r.content[:500]}" for r in results]
pair_vecs = await self.embedder.embed_batch(pairs)
for result, pair_vec in zip(results, pair_vecs):
rerank_score = cosine_similarity(query_vec, pair_vec)
blended = result.score * 0.3 + rerank_score * 0.7Esto aproxima un cross-encoder sin necesitar un modelo dedicado — los chunks donde el embedding combinado es más cercano al query-only son los más relevantes.
Adaptive threshold
Si el mejor resultado tiene un score bajo, el sistema relaja el umbral para no retornar vacío:
if ranked:
best_score = ranked[0].score
adaptive_threshold = min(threshold, best_score * 0.5)
ranked = [r for r in ranked if r.score >= adaptive_threshold]Context expansion
Si los chunks son pequeños (promedio < 400 chars), el sistema expande la ventana de contexto de ±1 a ±2 chunks adyacentes para darle más contexto al LLM:
def _adaptive_window(results, base_window):
avg_chars = sum(len(r.content) for r in results) / len(results)
if avg_chars < 400:
return base_window + 1 # ±2 en vez de ±1
return base_windowAgente RAG
El agente usa Pydantic AI con 4 tools que el LLM invoca autónomamente:
rag_agent = Agent(
_build_model(), # OpenAI-compatible (Ollama, OpenAI, etc.)
deps_type=AgentDeps,
system_prompt=SYSTEM_PROMPT,
)
@rag_agent.tool
async def search_knowledge_base(ctx, query: str, max_results: int = 5):
"""Hybrid search across ALL documents."""
results = await ctx.deps.retriever.hybrid_search(
query=query, top_k=max_results,
doc_filter=ctx.deps.document_id,
expand_context=True,
)
return [{"content": r.content, "score": r.score, ...} for r in results]Los 4 tools:
| Tool | Cuándo lo usa el agente |
|---|---|
search_knowledge_base | Preguntas generales sobre los documentos |
search_in_document | Preguntas sobre un documento específico |
list_available_documents | ”¿Qué documentos tienes?” |
summarize_document | ”Resume este documento” |
El agente decide qué tools llamar, puede hacer múltiples búsquedas con queries reformulados para preguntas complejas, y cita las fuentes con sección y título del documento.
Streaming
La respuesta se transmite token a token via SSE:
async with rag_agent.iter(prompt, deps=deps, message_history=history) as run:
async for node in run:
if rag_agent.is_model_request_node(node):
async with node.stream(run.ctx) as stream:
async for event in stream:
if isinstance(event, PartDeltaEvent):
delta = event.delta.content_delta
yield f"data: {json.dumps({'type': 'text', 'content': delta})}\n\n"Cada evento SSE tiene un tipo: text (token del LLM), tool_start (agente invocó un tool), sources (queries usados), end (fin del stream).
Multi-provider LLM
El LLM es intercambiable sin re-indexar documentos. Todo usa el protocolo OpenAI (/v1/chat/completions):
def _build_model():
if s.llm_provider == "openai":
provider = OpenAIProvider(api_key=s.llm_api_key)
elif s.llm_provider == "openai-compatible" and s.llm_base_url:
provider = OpenAIProvider(base_url=s.llm_base_url, api_key=s.llm_api_key)
else: # ollama
provider = OpenAIProvider(base_url=f"{s.ollama_base_url}/v1", api_key="ollama")
return OpenAIModel(s.llm_model, provider=provider)| Provider | Base URL | Modelo |
|---|---|---|
| Ollama (default) | localhost:11434 | qwen3.5:27b |
| OpenAI | api.openai.com | gpt-4o-mini |
| OpenRouter | openrouter.ai/api/v1 | claude-sonnet, llama, mistral |
| Groq | api.groq.com/openai/v1 | llama-3.3-70b |
| Inferencer Pro | mac-studio.local:54321/v1 | modelos locales |
Los embeddings son independientes del LLM — puedes usar Ollama para embeddings y Groq para chat, o Inferencer Pro para ambos.
Sesiones persistentes
Las conversaciones se persisten en SQLite con historial completo:
CREATE TABLE sessions (
id TEXT PRIMARY KEY,
title TEXT NOT NULL DEFAULT 'New Chat',
document_id TEXT,
created_at TEXT NOT NULL,
updated_at TEXT NOT NULL
);
CREATE TABLE messages (
id TEXT PRIMARY KEY,
session_id TEXT NOT NULL,
role TEXT NOT NULL CHECK(role IN ('user', 'assistant', 'system')),
content TEXT NOT NULL,
sources TEXT,
FOREIGN KEY (session_id) REFERENCES sessions(id) ON DELETE CASCADE
);El historial se pasa al agente como mensajes nativos de Pydantic AI, no como texto concatenado:
async def get_message_history(self, session_id, max_messages=10):
messages = []
for row in reversed(rows):
if row["role"] == "user":
messages.append(ModelRequest(parts=[UserPromptPart(content=row["content"])]))
elif row["role"] == "assistant":
messages.append(ModelResponse(parts=[TextPart(content=row["content"])]))
return messagesMemoria cross-session
En v0.4.0, cada sesión empezaba de cero. Ahora el agente recuerda preferencias, hechos y temas entre sesiones.
Después de cada respuesta, el sistema extrae automáticamente información duradera usando una llamada ligera al LLM:
_EXTRACTION_PROMPT = """
Extract user preferences or facts from this exchange.
Return ONLY a JSON array. Categories: preference, fact, topic.
"""
async def extract_memories(user_message, assistant_response):
# Llama al LLM con un prompt corto
# Parsea JSON con fallback regex para LLMs locales
# Retorna: [{"category": "preference", "content": "..."}]Las memorias se guardan en SQLite con deduplicación:
CREATE TABLE memories (
id TEXT PRIMARY KEY,
category TEXT NOT NULL,
content TEXT NOT NULL,
source_session TEXT,
created_at TEXT NOT NULL,
UNIQUE(category, content) -- evita duplicados
);Antes de cada llamada al agente, las últimas 20 memorias se inyectan en el prompt:
[MEMORY] You remember these facts about the user:
- Prefers responses in Spanish with bullet points
- Interested in API security
- Works with Kubernetes clusters
{mensaje del usuario}La extracción es best-effort — si falla (JSON inválido, timeout), el chat no se interrumpe. Las memorias se pueden ver y borrar desde la API (GET /api/memories, DELETE /api/memories/{id}) o desde las apps móviles.
Apps nativas
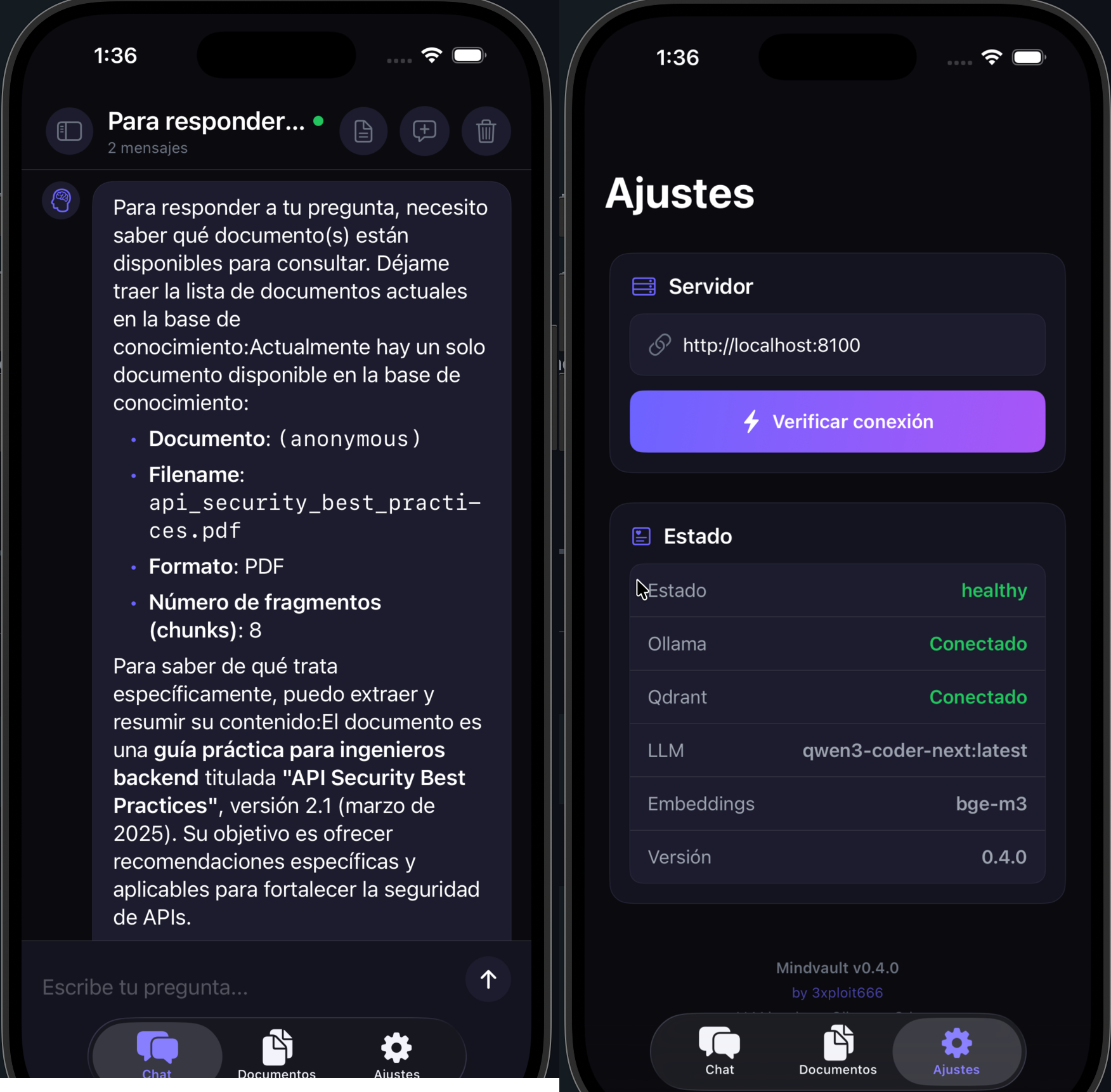
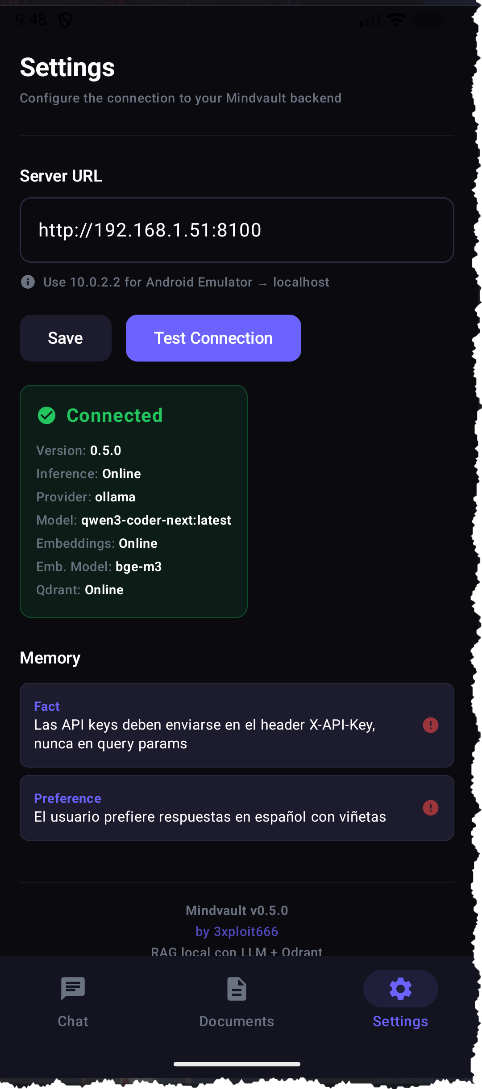
Ambas apps implementan:
- SSE streaming — tokens del LLM aparecen en tiempo real
- Upload de documentos — con barra de progreso via SSE
- Gestión de sesiones — crear, listar, eliminar conversaciones
- Health check — estado de inferencia, embeddings, Qdrant
- Markdown rendering — syntax highlighting con tema Dracula
- Dark mode — tema oscuro nativo
Las apps son clientes puros — toda la lógica de RAG vive en el backend. Solo se configuran con la URL del servidor.
Health check
El endpoint /api/health verifica cada componente independientemente:
{
"status": "healthy",
"inference": true,
"inference_provider": "ollama",
"llm_model": "qwen3.5:27b",
"embeddings": true,
"embedding_model": "bge-m3",
"embedding_provider": "ollama",
"qdrant": true
}Si el LLM está online pero embeddings no, reporta "degraded". Si nada responde, "unhealthy". Esto permite diagnosticar rápido qué servicio falló.
Setup
git clone https://github.com/3xploit666/mindvault.git && cd mindvault
make setup # instala deps + crea .env
make qdrant-up # levanta Qdrant en Docker
ollama pull bge-m3 # modelo de embeddings (requerido)
ollama pull qwen3.5:27b # LLM (o el que prefieras)
make run-reload # arranca el backend con hot reload
make health # verifica que todo esté okAPI en http://localhost:8100 — docs interactivos en http://localhost:8100/docs.
Repo
El código es open source: github.com/3xploit666/mindvault
Incluye el backend completo, apps iOS y Android, documentación de API, guía de arquitectura, y un APK pre-compilado en el release v0.5.0.